
A simple architecture was proposed in Part I of this article to avoid down times during the Sitecore content and code deployments. In this article, the deployments problems related to search is discussed and a potential solution is illustrated.
What search technology to use?
A straight forward answer is .. NOT Lucene. Although it’s the default search provider for Sitecore, it doesn’t do well within a multi-instances environment as the instances of the index will often go out-of-sync. Other search providers can be use such as Solr, Coveo for Sitecore and Elastic search. Each of these technologies may require different setup/configuration to achieve the goal of this article.
The rest of this article is based on Solr – as it’s currently the alternate search technology provided by Sitecore – showing what the potential problems are and how to avoid these problems.
What part of the search can cause downtime during deployments?
Two things can go wrong here:
1. Solr configuration updates
If you implemented a new feature in your website that requires a Solr configuration updates (e.g. auto complete using NGram or “Did you mean …” spellchecking) then you have to be very careful about they way of pushing the schema/config updates to the Solr server.
One mistake that developers do is restarting the Solr server to force it to read the new updates. Once the service is restarted, Sitecore will immediately show the yellow screen of death and the site will go down till the Solr server is up and running again.
Thankfully, Solr has a very helpful feature – Reload – that allows loading the config updates without causing downtime. Here is a quote from the Solr wiki pages describing the Reload function
Load a new core from the same configuration as an existing registered core. While the “new” core is initalizing, the “old” one will continue to accept requests. Once it has finished, all new request will go to the “new” core, and the “old” core will be unloaded.
http://localhost:8983/solr/admin/cores?action=RELOAD&core=core0
This can be useful when (backwards compatible) changes have been made to your solrconfig.xml or schema.xml files (e.g. new <field> declarations, changed default params for a <requestHandler>, etc…) and you want to start using them without stopping and restarting your whole Servlet Container.
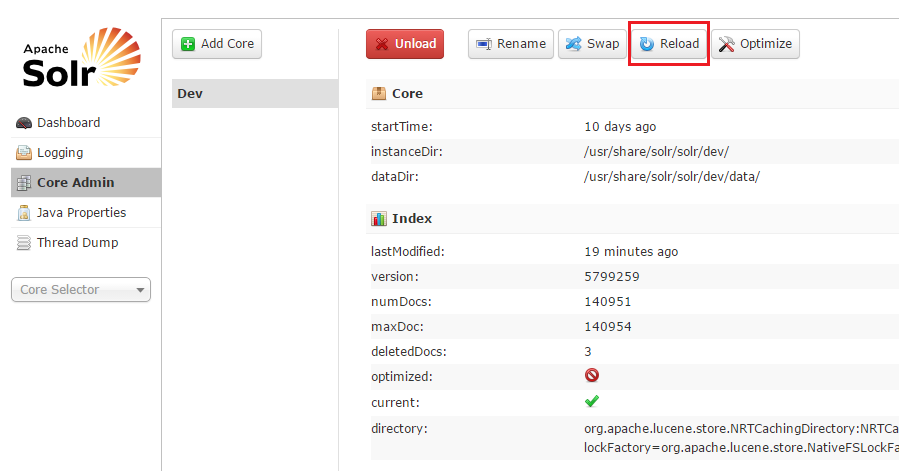
You can also reload a Solr core using the admin portal by going to “Core Admin” -> Click on the core you want to reload -> Click the Reload button as shown in the following screenshot:
2. Rebuilding the indexes
Another problem that you may face during deployments is the need to completely rebuild the index. The index rebuild process starts with deleting everything in the index, after that Sitecore processes the items to create the corresponding index document. Once the index rebuild process is started, the search functionality and any listing pages implemented using the Search APIs will not work till the indexing is done.
Imagine that you are rebuilding the index of an e-commerce website that contains thousands of product items along with their reviews, images, etc. You would expect that the indexing process won’t be quick, the more items you are indexing the more slower the process will be. Taking the website offline till the index process is finished won’t get appreciated by your client – especially if it’s an e-commerce and the client is loosing business because of the downtime.
In order to rebuild the index without a downtime, Sitecore utilizes the core Swap feature in Solr. Here, I am quoting the description of the Swap feature from the Solr wiki pages:
Atomically swaps the names used to access two existing cores. This can be useful for replacing a “live” core with an “ondeck” core, and keeping the old “live” core running in case you decide to roll-back.
So, you got the idea! when the Index Rebuild process is initiated, Sitecore will perform the indexing operation on a different core allowing the current core to serve the site users without any interruption to the service. Once the indexing process is finished, Sitecore will call the Swap command described above to swap the two cores.
Well, how to configure Sitecore to utilize the swap functionality then?
Assume that you are only concerned about the web database as it’s the only database affects the content delivery.
First thing you need to do is creating two in Solr cores for the web database, e.g. web_a and web_b.
Now go to the App_Config/Include/Sitecore.ContentSearch.Solr.Indexes.config and edit the index node of the web database from:
<!-- WEB INDEX configuration -->
<index id="sitecore_web_index" type="Sitecore.ContentSearch.SolrProvider.SolrSearchIndex, Sitecore.ContentSearch.SolrProvider">
<param desc="name">$(id)</param>
<param desc="core">web</param>
<param desc="propertyStore" ref="contentSearch/databasePropertyStore" param1="$(id)" />
<strategies hint="list:AddStrategy">
<strategy ref="contentSearch/indexUpdateStrategies/onPublishEndAsync" />
</strategies>
<locations hint="list:AddCrawler">
<crawler type="Sitecore.ContentSearch.SitecoreItemCrawler, Sitecore.ContentSearch">
<Database>web</Database>
<Root>/sitecore</Root>
</crawler>
</locations>
</index>
to:
<!-- WEB INDEX configuration -->
<index id="sitecore_web_index" type="Sitecore.ContentSearch.SolrProvider.SwitchOnRebuildSolrSearchIndex, Sitecore.ContentSearch.SolrProvider">
<param desc="name">$(id)</param>
<param desc="core">web_a</param>
<param desc="rebuildcore">web_b</param>
<param desc="propertyStore" ref="contentSearch/databasePropertyStore" param1="$(id)" />
<strategies hint="list:AddStrategy">
<strategy ref="contentSearch/indexUpdateStrategies/onPublishEndAsync" />
</strategies>
<locations hint="list:AddCrawler">
<crawler type="Sitecore.ContentSearch.SitecoreItemCrawler, Sitecore.ContentSearch">
<Database>web</Database>
<Root>/sitecore</Root>
</crawler>
</locations>
</index>
The first change in the configuration is replacing the instead the SolrSearchIndex class by its extended SwitchOnRebuildSolrSearchIndex class, also you will need to set the rebuildcore parameter to specify name of the secondary core.
Swapping the cores won’t happen unless you rebuild the index using one of the methods shown in the screenshots below.
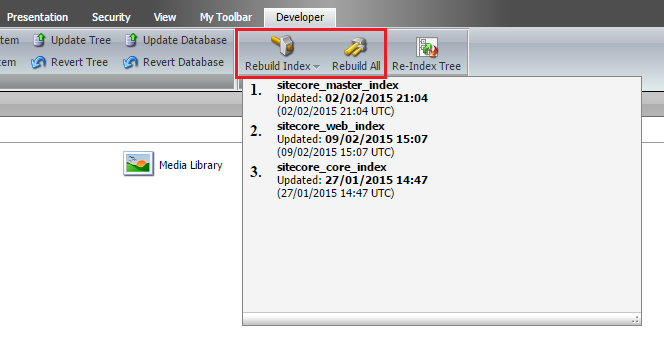
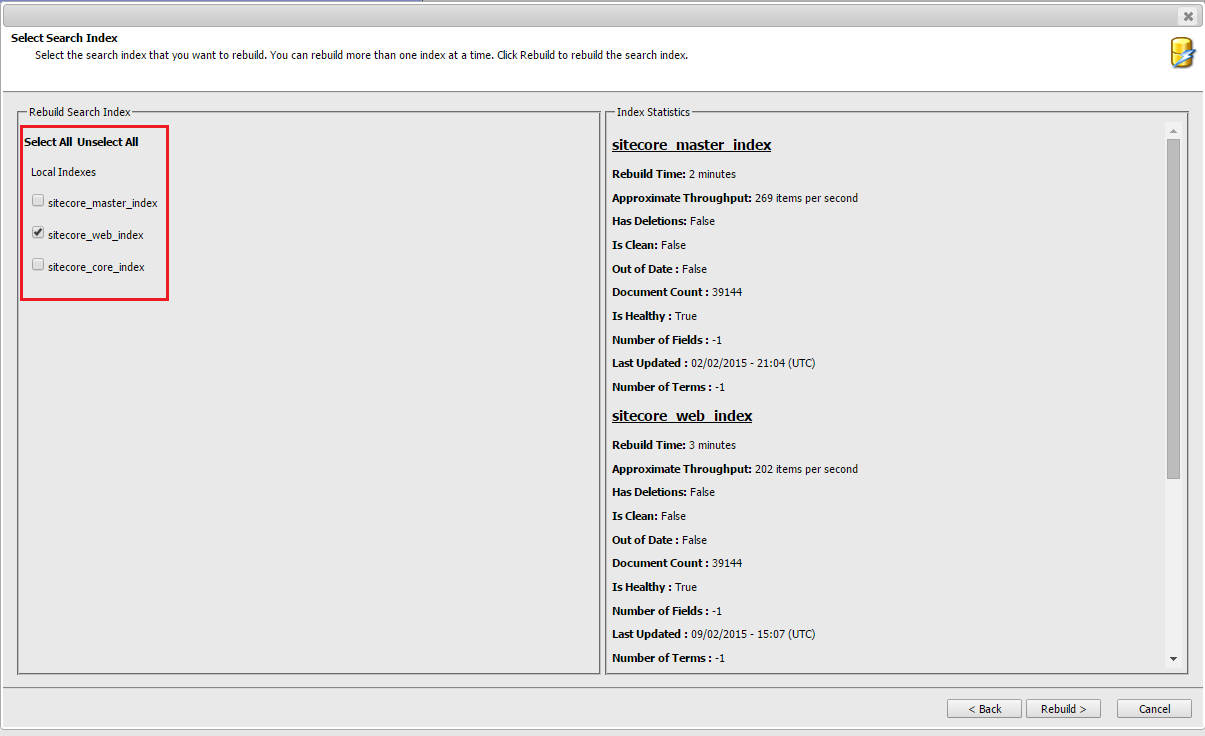
Now everything is setup in the right way and the index should never get deleted during the index-rebuild process.
Good to know about those features of SOLR. This looks like a pretty solid solution.
I feel sorry for all Sitecore/Lucene implementations 🙂
Lucene can be configured in a similar way to utilize an old index while a new one is being built. You have to change the type reference of the particular index to Sitecore.ContentSearch.LuceneProvider.SwitchIndexOnRebuild which is documented in the Search and Indexing Guide.
You still obviously have the limitation where indexes could get out of sync.
Didn’t know you can do this in Lucene! Thanks for sharing this.
Good articles! I have a question though. How do you deal with SOLR indexes with a “rolling” (no downtime) deployment that uses two web databases like you described in part 1? A recommended setup for SOLR is to have one CD orchestrate the index update on publish:end:remote. The others should use manual strategy or no strategy (this is straight from the scaling guide). It’s all good until you start deploying/publishing to CDs one by one. Let’s take a look at the example in the part I. There’s a delay (a noticeable delay to be precise) between content/code update to CD1 and CD2. If CD1 triggers index update in SOLR it may hurt CD2 once it’s done because of content mismatch (what’s been indexed and what’s in the web database attached to that CD). If CD2 does it then it hurst CD1 for exact same reason when it (CD1) is brought back online. Any good recommendation on how to keep everyone happy without duplicating SOLR cores (and getting back to “indexes not in sync / not timed between CDs” problem that we had with Lucene)?
Hi Pavel, this is a really interesting question.
I am thinking out load here :), haven’t tried this solution but here what I would do:
1) Create a new second web solr core “WebCore2”. -> no intention to use this core simultaneously with the existing core .. to avoid the sync and timing issues.
2) After you take CD1 off the cluster, configure CD1 to point to “WebCore2”
3) Finish the deployment on CD1
4) When you publish to CD1, the index will get rebuilt on the tempCore and won’t affect the live CD2 server
5) Bring CD1 live and take CD2 off the cluster. At this point, CD2 is pointing to the old solr core. However, it’s not publicly accessible.
6) Deploy to CD2
7) Publish (at this server may have not an index strategy as you mentioned)
8) Configure CD2 to point to “WebCore2”
9) Bring CD2 live
Please let me know if this makes any sense
It does. You would only need to make sure you always do the rolling deployment in the same order. In a multi-CD environment you are probably triggering reindexing from one CD and let the rest of the crowd enjoy the ride, right? The CD that triggers re-indexing should be deployed to first and you should always remember to swap the cores. Add to that a SOLR cluster or a multi-core setup to split the index and put that one into a cluster 🙂 and the whole thing becomes really non-trivial. Plus now you can’t publish content while you’re deploying a new version. Shouldn’t be a problem unless you’re running a multi-tenant setup. Yet another layer of complexity. Some other CMSs handle it in a little different way with publishing queues that you can keep around but turn off the agents so that content flows to those delivery servers that are “allowed” to receive it but gets queued up for the rest. Anyway. Good conversation! Thanks again for a thought-provoking blog post.